This is the first post in a series I want to write regarding various solutions or patterns of which I have always had theoretical knowledge, and which sometimes I haven't had the opportunity to implement, starting with request caching mechanisms.
From a theoretical point of view, I understand that it will help me strengthen knowledge in these areas. Furthermore, I hope that in some of these practical examples, I can illustrate the differences between various mechanisms and truly corroborate the scenarios where these patterns or solutions are appropriate.
As I mentioned earlier, I'm going to start with solutions for request caching. In general, when trying to access a REST API, if there is an operation that has no side effects and is idempotent, it is a good candidate for the responses of those requests to be cached, so it is not necessary to access that resource in the service because that information was already obtained in a previous request. Among the operations defined for a REST API that could be cacheable would be the GET operation, provided it has no side effects (implemented as the specification says without modifying anything) and is idempotent (there are times when the operation is not idempotent, for example, when some kind of counter is kept for how many times that operation has been executed).
For this example, I have assumed that the operation will be a GET, which is presumed to meet the conditions indicated above.
All the mechanisms I know for controlling such caching at the REST API level are based on headers returned as part of the response, acting accordingly based on that information.
The headers I know for this request caching control are:
- Expires
- Cache Control
- eTag
- Last Modified
Each has a different use and a different place where this caching can be performed. With this set of headers, there are two ways to interpret request caching:
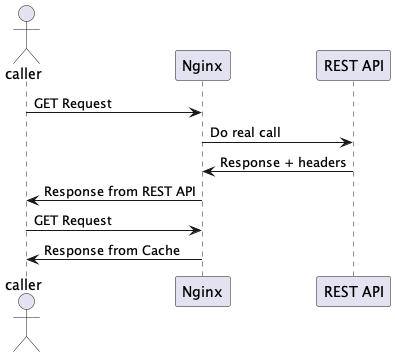
- We have an intermediate agent between the caller and the REST API (a proxy) which is capable of using those return headers to determine if it is necessary to go to the REST API again when a second request is made.
- Offering the possibility for the caller to identify that in a second request to the same service nothing has changed. For example, a system that displays a person's data and refreshes that view after each operation in the application can make the request and identify that nothing has changed, avoiding internal state changes.
To have a local system where these scenarios can be simulated, I have prepared a repository at https://github.com/chintoz/solution-cache-request-mechanism which shows the behavior of these headers. For this, an application has been set up with docker-compose with layers as follows:
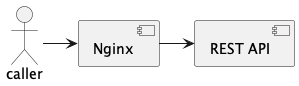
And for example, for the first interpretation of request caching, behavior like the following would be expected:
The project's README indicates how to launch the project and the existing endpoints to demonstrate each case.
Caching from the Server Point of View
Mechanisms based on the Expires and Cache Control headers allow server-side control to identify whether the request needs to be performed again or not.
In this case, NGINX would be responsible for using these headers to identify whether the previously performed request, whose result it has saved, needs to be performed again or not.
The main difference between both headers is the information they carry:
- Expires contains a date for when the resource expires: Sat, 02 Sep 2023 22:46:38 GMT
- Cache Control provides information about the validity time of that response: max-age=86400 (there are more values configured at the Cache Control level, such as whether request caching should be performed or not...)
In the example shown in the code, the endpoints under the paths /cached/expires and /cached/cacheControl have a response delay of about 10 seconds. In this way, we can see that the first invocation passes through all layers and reaches the API, which takes 10 seconds to give us the response, but subsequent requests are served directly by the cache found in the NGINX layer, serving them immediately.
The following image shows how the first requests take 10 seconds and the second ones are barely served by NGINX:

This is an example of using these headers when the resource we want to access has a negative impact on performance, as it is a quite "heavy" resource to obtain.
Caching from the Client Point of View
The other two headers that can be used from a client point of view are eTag and Last Modified.
With these headers we can identify from the point of view of a client that makes frequent requests to the same resource whether changes have occurred, if they actually have or not.
These headers allow us to identify that a resource we accessed previously has not been modified, receiving a 304 response from the server, indicating that the document has not undergone changes.
Actually, from the point of view of the NGINX we have in front of our API, the request ends up being made, because in reality the information that comes in these headers is not relative to the validity of that response, but this header defines a way to identify if a resource has been modified or not.
Furthermore, from the caller's point of view, the type of response received is not a type 200 response, but a type 304 response (no content) is returned, identifying that no action needs to be taken.
The main difference between both headers is the information they carry:
- eTag carries information such as a kind of hash code of the returned document, so that if a change occurs in that document, the hash code value will be different: 1693011640000
- Last Modified provides information on when the document was last modified, so if the result of the next call gets the same timestamp value, it will denote that the content is the same: Sat, 26 Aug 2023 01:00:40 GMT
In these cases, the main performance impact will be on the caller's side. In case we have a client that has to update data periodically and the graphical interface update process is heavy, this mechanism can help reduce that impact, performing that update only when there is new content to display.
To check these examples, use the following API accesses: /cached/eTag and /cached/lastModified.
Conclusion
Many times improvements over APIs are considered only from the point of view of what we can do in the API itself, whether they are caches for data access, indexes, etc., trying to give our API better performance.
In some scenarios, it can overly complicate our API when sometimes it is sufficient to perform operations to avoid our API being called and delegate that responsibility to an API Gateway (in our repository, NGINX was performing that function).
In that case, there are various headers that we can use, which provide us with some control over what information is being returned, how long it is valid, or when it was last modified.
Not everything is positive with this type of solution. Like all request caching mechanisms, the problem arises when that data is modified and we have to invalidate that cache. Depending on the update frequency of that data, one must decide which mechanism best fits their needs.